Guide to Data Cleaning in '24: Steps to Clean Data & Best Tools
Since data is the fuel of machine learning and artificial intelligence technology, businesses need to ensure the quality of data. Though data marketplaces and other data providers can help organizations obtain clean and structured data, these platforms don’t enable businesses to ensure data quality for the organization’s own data. Therefore, businesses need to understand the necessary steps of a data cleaning strategy and use data cleaning tools to eliminate issues in data sets.
Data cleaning (or data cleansing, data scrubbing) broadly refers to the processes that have been developed to help organizations have better data. These processes have a wide range of benefits for any organization that chooses to implement them, but better decision making may be the one that comes to mind first.
Some common questions related to data cleaning that we cover in this post include:
What is data cleaning?
Data cleaning, or cleansing, is the process of correcting and deleting inaccurate records from a database or table. Broadly speaking data cleaning or cleansing consists of identifying and replacing incomplete, inaccurate, irrelevant, or otherwise problematic (‘dirty’) data and records.
With effective cleansing, all data sets should be consistent and free of any errors that could be problematic during later use or analysis.
How are data cleaning and data migration related?
Data migration is the process of extracting data from one location and transferring it to another. Although the process might seem simple, its main challenge is that location where the extracted data will ultimately be housed in might already contain duplicates, be incomplete, or could be wrongly formatted.
Explore 7 best data migration tools and best practices.
Why do we need data cleaning?
Data is arguably one of the most vital assets an organization has to help support and guide its success. According to an IBM study, poor data quality costs 3.1 trillion dollars per year in the US. Poor quality data should be fixed immediately as seen on the graph below, cost of poor data increases exponentially according to the 1-10-100 quality principle.

Some examples of problems that can arise out of inaccurate data are:
Business functions
- Marketing: An ad campaign using low-quality data and reaching out to users with irrelevant offers. This not only reduces customer satisfaction but also misses a significant sales opportunity.
- Sales: A sales representative failing to contact previous customers, because of not having their complete, accurate data.
- Compliance: Any online business receiving penalties from the government by not meeting data privacy rules for its customers. Therefore data cleansing vendor should provide you sufficient guarantees that data will be processed within the GDPR compliance framework.
- Operations: Configuring robots and other production machines based on low-quality operational data, can cause causes major problems for manufacturing companies
Industries
- Healthcare: In healthcare, dirty may lead to wrong treatments and failed pharmaceutical drugs. According to an Accenture survey, 18 percent of health executives believe that lack of clean data is the main obstacle for AI to reach the real potential in healthcare.
- Accounting&finance: Inaccurate and incomplete data can lead to regulatory breaches, delayed decisions due to manual checks, and sub-optimal trade strategies.
- Manufacturing&logistics: Inventory valuations depend on accurate data. If data is missing or inconsistent, this may lead to delivery problems and unsatisfied customers.
Clean data enables organizations to avoid these situations and problems.
What are the benefits of data cleaning?
Better quality data impacts every activity that includes data. Almost all modern business processes involve data. Subsequently, when data cleaning is seen as an important organizational effort, it can lead to a wide range of benefits for all. Some of the biggest advantages include:
- Streamlined business practices: Imagine if there are no duplicates, errors, or inconsistencies in any of your records. How much more efficient would all of your key daily activities become?
- Increased productivity: Being able to focus on key work tasks instead of finding the right data or having to make corrections because of incorrect data is essential. Having access to clean high-quality data, with the help of effective knowledge management can be a game-changer.
- Faster sales cycle: Marketing decisions depend on data. Giving your marketing department the best quality data possible means better and more leads for your sales team to convert. The same concept applies to B2C relationships too!
- Better decisions: We touched on this before, but it’s important enough that it’s worth repeating. Better data = better decisions.
These different benefits in conjunction generally lead to a business that is more profitable. This is not only because of better external sales efforts but also because of more efficient internal efforts and operations.

image source: Analytics India Magazine
What are the different types of data issues?
Various types of data issues occur when businesses combine datasets from multiple places, scrape data from web or receive data from clients/other departments. Some example data issues are:
- Duplicate data: There are 2 or more identical records. This may cause misrepresentation of inventory counts/duplication of marketing collateral or unnecessary billing activities.
- Conflicting Data: When there are same records with different attributes, it means data is conflicting. For example, a company with different versions of addresses may cause delivery issues.
- Incomplete Data: The data that has missing attributes. Payrolls of employees may not be processed due to their missing social security numbers in the database.
- Invalid Data: Data attributes are not conforming to standardization. For example, 9 digit phone number records rather than 10 digits.
What are the root causes of data issues?
Data issues arise due to technical problems such as:
- Synchronization issues: When data is not appropriately shared between two systems, it may also cause a problem. For example, a banking sales system captures a new mortgage but fails to update the bank’s marketing system, then the customer may confuse if they get a message from the marketing department.
- Software bugs in data processing applications: Applications can write data with mistakes or overwrite correct data due to various bugs.
- Information Obfuscation by users: It is the concealment of data by purpose. People may give incomplete or incorrect data to safeguard their privacy.
What is high-quality data?
There are a few criteria that help to qualify data as high quality. They are:
- Validity: How closely the data meets defined business rules or constraints. Some common constraints include:
- Mandatory constraints: Certain columns cannot be empty
- Data-type constraints: Values in a column must be of a certain data type
- Range constraints: Minimum and maximum values for numbers or dates
- Foreign-key constraints: A set of values in a column are defined in the column of another table containing unique values
- Unique constraints: A field or fields must be unique in a dataset
- Regular expression patterns: Text fields will have to be validated this way.
- Cross-field validation: Certain conditions that utilize multiple fields must hold
- Set-membership constraint: This one is the subcategory of foreign-key constraints. Values for a column come from a set of discrete values or codes.
- Accuracy: How closely data conforms to a standard or a true value.
- Completeness: How thorough or comprehensive the data and related measures are known
- Consistency: The equivalency of measures across systems and subjects
- Uniformity: Ensuring that the same units of measure are used in all systems
- Traceability: Being able to find (and access) the source of the data
- Timeliness: How quickly and recently the data has been updated
These different characteristics together can help an organization have data that is high quality and can be used for a wide range of purposes with minimal need for educated hypothesizing.
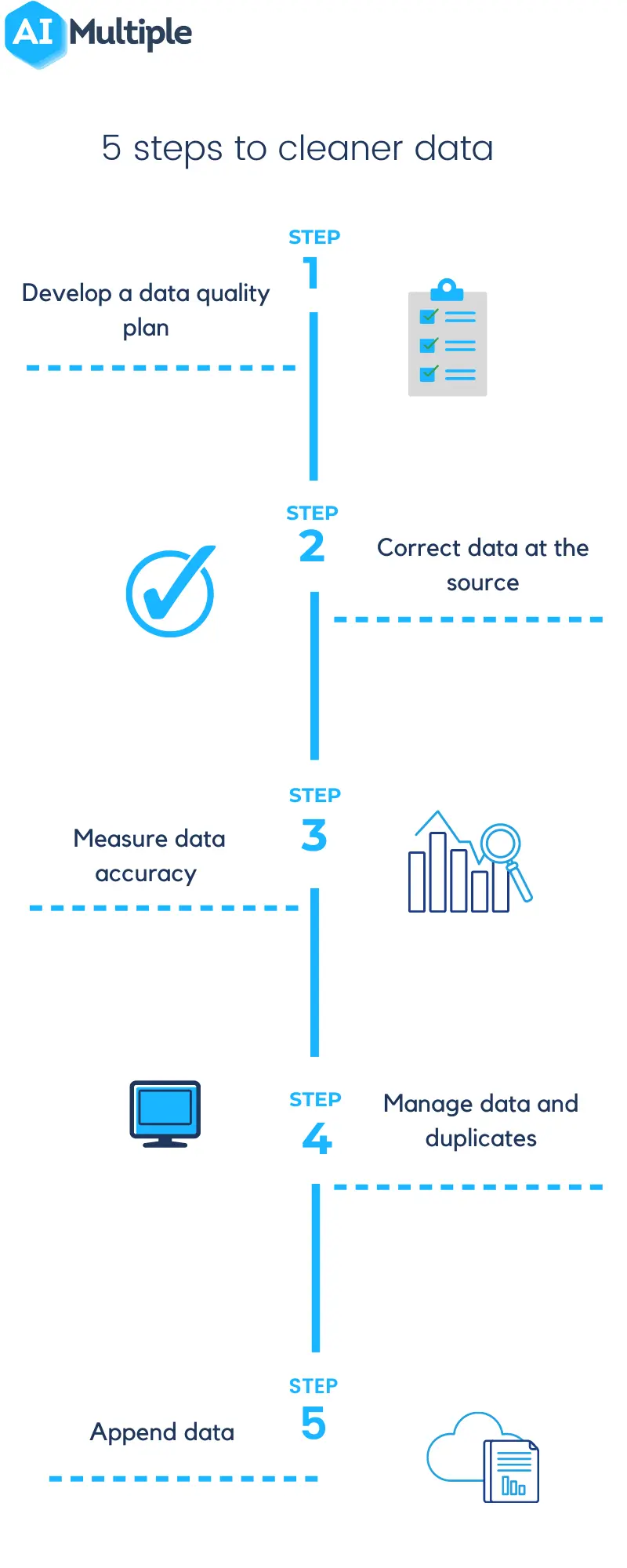
5 steps to cleaner data
Want cleaner data? Sometimes it can be helpful to consider bringing on an outside consultant to help you begin. However, before you do that, there are a few general steps that any organization can follow to start getting into a better data cleaning mindset:
#1 Develop a data quality plan
It is essential to first understand where the majority of errors occur so that the root cause can be identified and a plan built to manage it. Remember that effective data cleaning practices will have an overarching impact throughout an organization, so it is important to remain as open and communicative as possible. A plan needs to include
- Responsibles: A C-Level executive, Chief Data Officer (CDO) if the company already appointed such an executive. Additionally, business and tech responsible need to be assigned for different data
- Metrics: Ideally, data quality should be summarizable as a single number on a 1-100 scale. While different data can have different data quality, having an overall number can help the organization measure its constant improvement. This overall number can give more weight to data that are critical to the companies success, helping prioritize data quality initiatives that impact important data.
- Actions: A clear set of actions should be identified to kick off the data quality plan. Over time, these actions will need to be updated as data quality changes and as companies priorities change.
#2 Correct data at the source
If data can be fixed before it becomes an erroneous (or duplicated) entry in the system, it saves hours of time and stress down the line. For example, if your forms are overcrowded and require too many fields to be filled, you will get data quality issues from those forms. Given that businesses are constantly producing more data, it is crucial to fix data at the source.
#3 Measure data accuracy
Invest in the time, tools, and research necessary to measure the accuracy of your data in real-time. If you need to purchase a data quality tool to measure data accuracy, you can check out our data quality tools article where we explain the selection criteria for the right data quality tool.
#4 Manage data and duplicates
If some duplicates do sneak past your new entry practices, be sure to actively detect and remove them. After removing any duplicate entries, it is important to also consider the following:
- Standardizing: Confirming that the same type of data exists in each column.
- Normalizing: Ensuring that all data is recorded consistently.
- Merging: When data is scattered across multiple datasets, merging is the act of combining relevant parts of those datasets to create a new file.
- Aggregating: Sorting data and expressing it in a summary form.
- Filtering: Narrowing down a dataset to only include the information we want
- Scaling: Transforming data so that it fits within a specific scale such as 0-100 or 0-1
- Removing: Removing duplicate and outlier data points to prevent a bad fit in linear regression.
#5 Append data
Append is a process that helps organizations to define and complete missing information. Reliable third party sources are often one of the best options for managing this practice.
Upon completing these 5 steps, your data will be ready to be exported to a data catalog and be used when the analysis is needed. Remember that with large datasets, 100% cleanliness is next to impossible to achieve.
Data Cleaning Techniques
As is the case with many other actions, ensuring the cleanliness of big data presents its own unique set of considerations. Subsequently, there are a number of techniques that have been developed to assist in cleaning big data:
Conversion tables: When certain data issues are already known (for example, that the names included in a dataset are written in several ways), it can be sorted by the relevant key and then lookups can be used in order to make the conversion.
Histograms: These allow for the identification of values that occur less frequently and may be invalid.
Tools: Every day major vendors are coming out with new and better tools to manage big data and the complexities that can accompany it.
Algorithms: Such as spell check or phonetic algorithms can be useful – but they can also make the wrong suggestion.
About Manual Data Interventions
Today it is almost never economic to manually edit data for improvement. However, in case of extremely valuable data or when millions of labeled data points are needed as in the case of image recognition systems, manual data updates may make sense. If manual updates will be made on the data, some best practices to keep in mind include:
- Be sure to sort data by different attributes
- In the case of larger datasets, try breaking them down in down into smaller sets to increase iteration speed
- Consider creating a set of utility functions such as remapping values based on CSV file or regex search-and-replace
- Keep records of every cleaning operation
- Sampling can be a great way to assess quality. Once you know your data quality tolerance limits, these can help you decide sample size to assess quality. For example, if you have 1,000 rows and need to make sure that a data quality problem is no more common than 5%, checking 10% of cases
- Analyze summary statistics such as standard deviation or number of missing values to quickly locate the most common issues
Keeping these in mind throughout any manual data cleaning initiative can help to ensure the ongoing success of the project.
Best practices in data cleaning
There are several best practices that should be kept in mind throughout any data cleaning endeavor. They are:
- Consider your data in the most holistic way possible – thinking about not only who will be doing the analysis but also who will be using the results derived from it
- Increased controls on database inputs can ensure that cleaner data is what ends up being used in the system
- Choose software solutions that are able to highlight and potentially even resolve faulty data before it becomes problematic
- In the case of large datasets, be sure to limit your sample size in order to minimize prep time and accelerate performance
- Spot check throughout to prevent any errors from being replicate
- Leverage free online courses like data science competition platform Kaggle’s data cleaning courses if you want to handle data cleaning internally and your data team doesn’t have enough experience in data cleaning.
Challenges of data cleaning

Image source: Preact CRM
Data cleaning, though essential for the ongoing success of your organization, is not without its own challenges. Some of the most common include:
- Limited knowledge about what is causing anomalies, creating difficulties in creating the right transformations
- Data deletion, where a loss of information leads to incomplete data that cannot be accurately ‘filled in’
- Ongoing maintenance can be expensive and time-consuming
- It is difficult to build a data cleansing graph to assist with the process ahead of time
For more on data
To learn more about data, read:
- The Ultimate Guide to Data Management & How AI Can Help
- DataOps: What it is, Benefits and Importance
- Data Orchestration to Get the Most from Your Data
Finally, if you believe your business would benefit from a data software, head over to our data hub, where you will find data-driven lists of vendors for different data applications.
And if you still have questions about data cleaning processes and vendors, we would like to help:

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
Feature Engineering: Processes, Techniques & Benefits in 2024
Data Quality Tools & Criteria for Right Tools [2024 update]

Thanks for sharing the lovely information about outsourcing data cleansing. That will be understood by the newcomer and clear all the queries.

We are glad you enjoyed the article!

Hi Cem,
Great article regarding bad data – just want to add a comment regarding the impact, going beyond the monetary cost you noted.
I work for BaseCap Analytics as a financial data consultant, and we have helped SIFIs and investment firms address data issues.
We have found that bad data also has a profound effect on the morale of everyone involved in the data lifecycle – creating riffs between departments.
So just you suggested, it is important that organizational leadership treat data quality control as a foundational building block of their data governance framework.

How much do you keep up with current data cleansing tools? My team and I are looking over several options, and were intrigued by this platform https://www.bisok.com/data-science-workbench/data-cleansing-tools/ . Thanks in advance
Comments
Your email address will not be published. All fields are required.